

Researchers are now using reinforcement learning from human feedback (RLHF) method to train models such as GPT-4. This method can be simply explained as follows: people give marks for each response of the model, with the subsequent task of learning how to generate responses that achieve high scores (as judged by the person).
However, this approach has at least two disadvantages. Firstly, since people are involved in the RLHF method, we have a "bottleneck": human verification and labeling of each answer is a complex and expensive process. Secondly, OpenAI believes that superintelligence — AI that is much smarter than humans — will be created within the next ten years. Therefore, people will not be able to train artificial intelligence that is smarter than them.
A core challenge for aligning future superhuman AI systems (superalignment) is that humans will need to supervise AI systems much smarter than them.
OpenAI
Since we do not have superintelligence (probably fortunately), the only way to explore possible solutions to the described problem is to simulate a "toy" scenario. To do this, authors from OpenAI propose in their paper to train the GPT-4 model using GPT-2 as a teacher (supervisor) instead of a human.
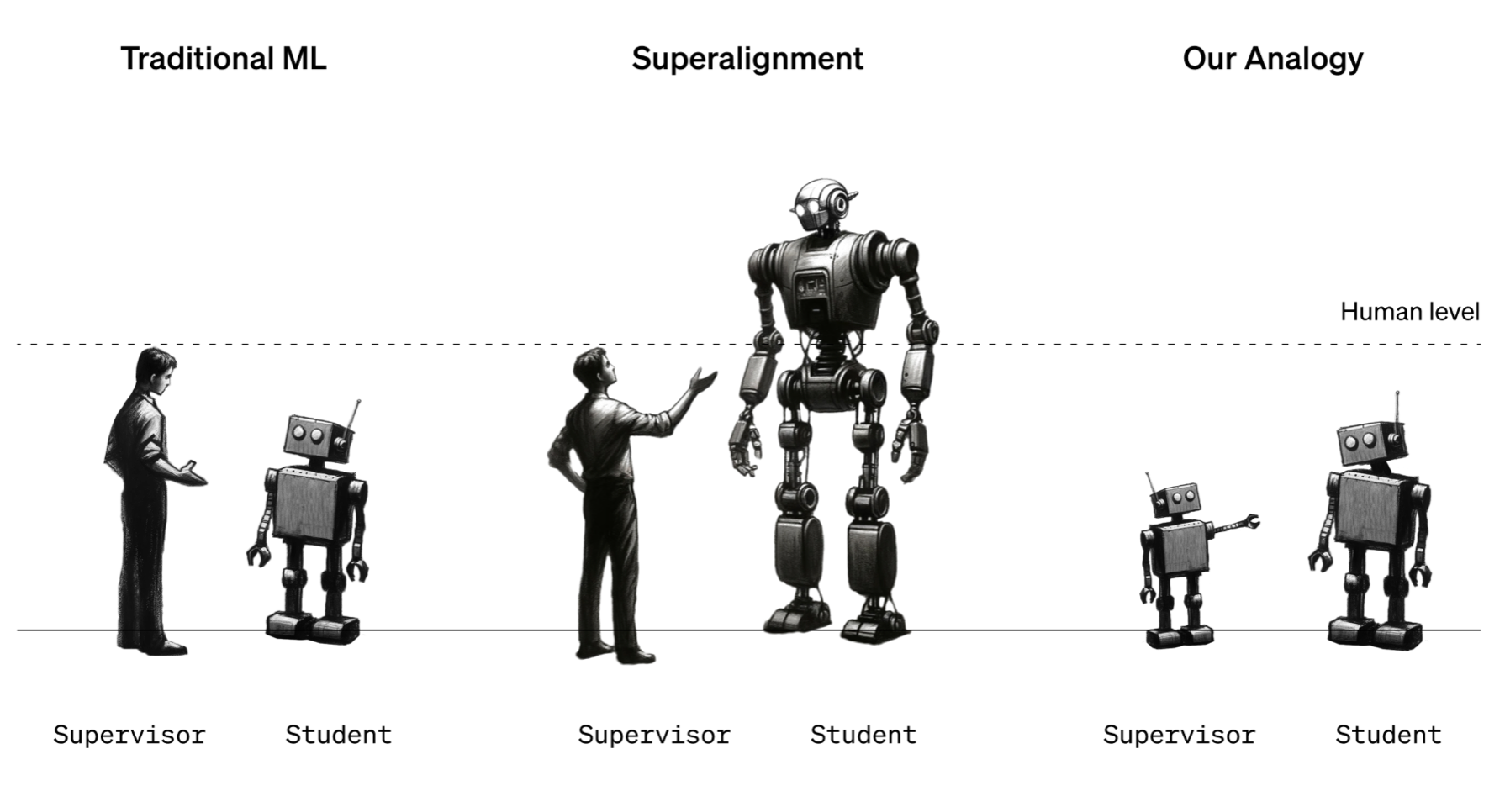
Proposed methodology
In this article, the authors solve three problems for their experiments: binary classification on 22 well-known datasets, predicting the best move in chess, and predicting the best LLM response according to a person. To do this, they fine-tune three pre-trained models:
- GPT-2 is fine-tuned on labeled datasets (the weak supervisor)
- GPT-4 is fine-tuned on predictions from the weak supervisor GPT-2 (the strong student model). That is, the weak model trains the strong model
- GPT-4 is also fine-tuned on labeled datasets. The authors consider this model as a model of the best quality, which they will strive for in further experiments (the strong ceiling performance)
Intuitively, it may seem that the GPT-4 model fine-tuned on predictions from GPT-2 will not be able to get better results than GPT-2. However, not everything is so simple. GPT-4 already has ideas about the environment: the model, even without additional training, can show not bad results on the tasks under consideration. That is, we do not need to train the neural network from scratch. It is necessary to identify the hidden knowledge of the model and adjust it. This task is much easier than training from scratch, and we can use predictions from the fine-tuned on labeled data GPT-2 model for this (weak-to-strong generalization).
The authors consider in their paper two approaches to fine-tune the strong model – a naive and an advanced. Let us briefly describe these approaches.
A naive approach
In a naive approach, the authors fine-tune the strong student model on the predictions from the weak supervisor for specific tasks. That is, the distribution of predictions from the strong student model becomes similar to the distribution of predictions from the weak supervisor. This approach risks the stronger model adopting the inaccuracies or biases of the weaker model.
An advanced approach
To solve the problem that arises with the naive approach, the authors propose an auxiliary confidence loss function:
\[ L_{\text{conf}}(f) = (1 - \alpha) \cdot CE(f(x), f_w(x)) \\ + \text{ } \underbrace{\alpha \cdot CE(f(x), \hat{f}_t(x))}_{\text{additional term}}, \]
where:
- \( CE(\cdot,\cdot) \) is the cross-entropy loss between the predictive distributions on a given input \( x \)
- \( f_w(x) \in [0,1] \) represents the weak label predictive distribution
- \( f(x) \in [0,1] \) is the strong model predictive distribution
- \( \hat{f}_t(x) \) correspond to hardened strong model predictions using a threshold \( t, \) i.e. \( \hat{f}_t(x) = I[f(x) > t] \in \left\{0, 1\right\}, \) where \( I \) is the indicator function. In this article, the authors set the threshold \( t \) adaptively
- \( \alpha \) is a weight
This loss function allows the authors to retain knowledge of a stronger model (GPT-4). In simple words, using this loss function during training, the following condition is added: if the strong student model's predictions significantly differ from the weak supervisor's predictions, then we do not need to heavily fine the student model. To do this, an additional term is added to the loss function, which increases the confidence of the strong model in its own forecasts, even if they do not match the predictions of the supervisor.
Results
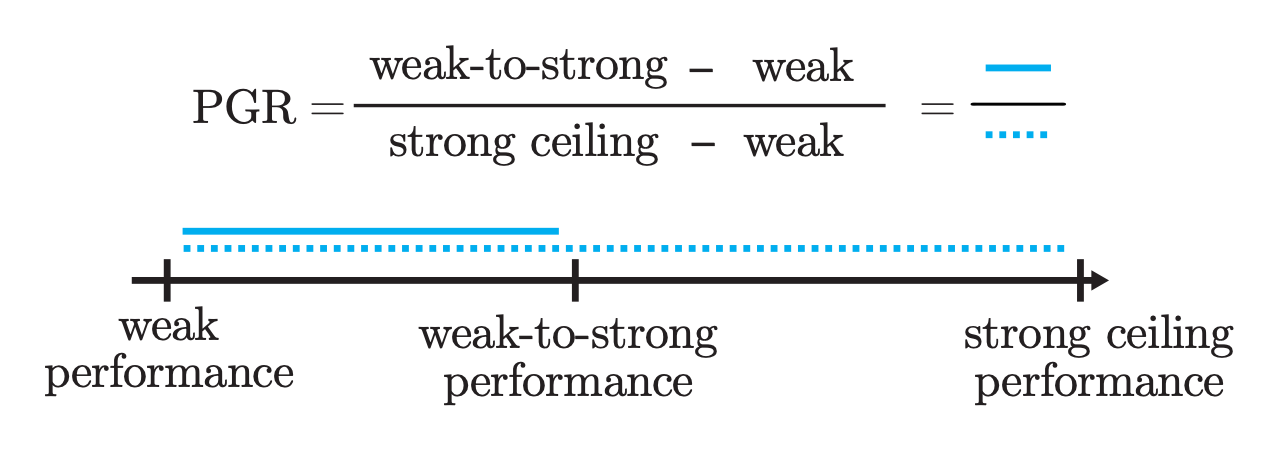
To evaluate the quality of the proposed approaches, the authors introduced the performance gap recovered (\( \text{PGR} \)) metric:
- If we achieve perfect weak-to-strong generalization, i.e., the strong student model has strong ceiling performance, \( \text{PGR} = 1 \)
- If the weak-to-strong model does not better than the weak supervisor, then \( \text{PGR} = 0 \)
According to the authors' experimental assessment, we can achieve \( \text{PGR} = 0.2 \) using a naive approach and \( \text{PGR} = 0.8 \) with an advanced fine-tuning approach. Thus, the proposed auxiliary confidence loss function allows the authors to reduce the quality gap between the GPT-2 and GPT-4 models by 80%.
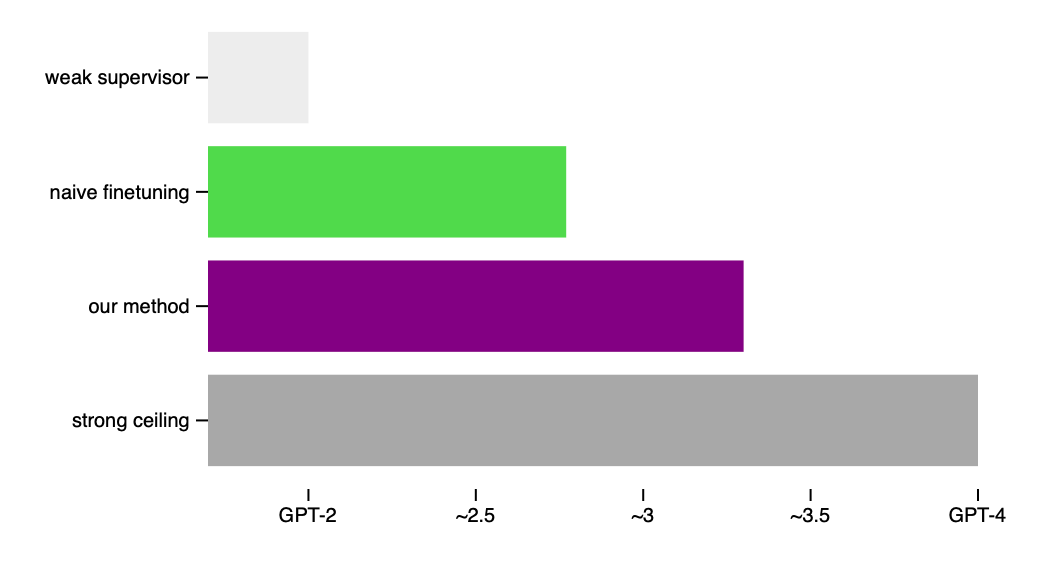
Thus, a strong model like GPT-4, when trained using the annotations from a weaker model like GPT-2, significantly surpasses the second one, coming very close to the case, as if a strong model was trained on labeled data. Interestingly, GPT-4 fine-tuned using the proposed methodology produces results similar to those of the GPT-3.5 model trained on labeled data.
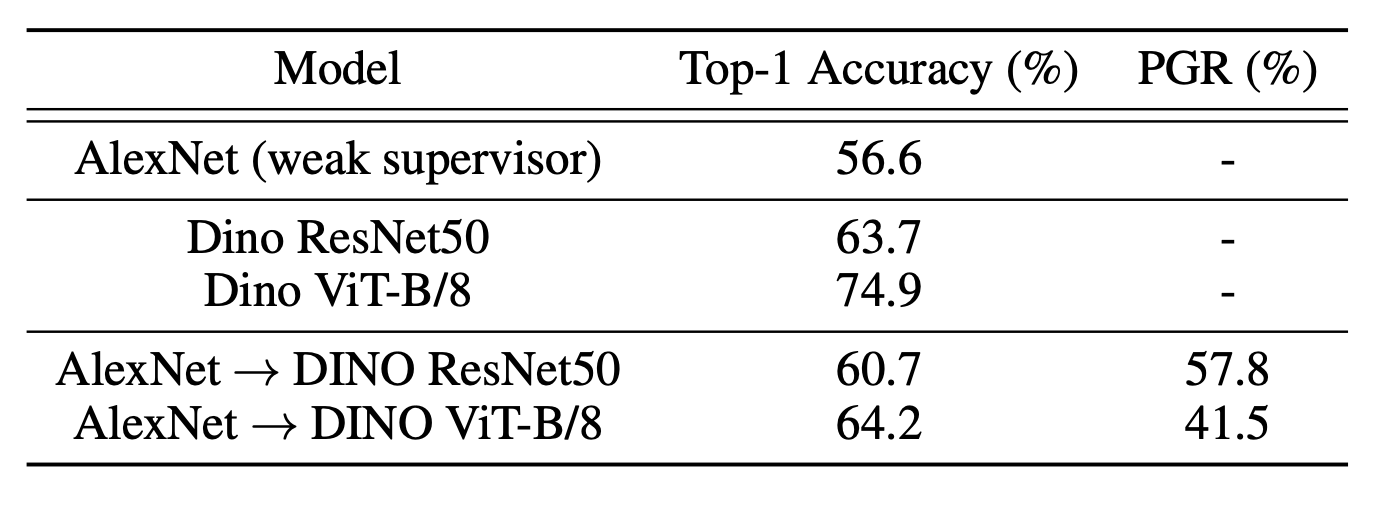
As a computer vision researcher, I was curious to test the methodology proposed in this article on computer vision tasks. The authors did it for me: they chose AlexNet as the weak supervisor, ResNet (ViT) self-supervised pre-trained using the DINO strategy as the strong student model. And they demonstrated that the proposed methodology makes it possible to increase the model's (ResNet or ViT) quality in the classification task on the ImageNet dataset.
Conclusion
The methodology for weak-to-strong generalization proposed in the OpenAI's paper opens the direction for subsequent research on the topic of replacing reinforcement learning from human feedback (RLHF) method by a strategy in which AI will teach another AI. Potentially, in the future, we will be able to replace GPT-2 and GPT-4 in a "toy" scenario by two superintelligence models. However, before that, several more significant discoveries must be made.




