

I'm excited to announce that our paper "ReMix: Training Generalized Person Re-identification on a Mixture of Data" has been accepted at Winter Conference on Applications of Computer Vision (WACV 2025). In this work, we present the ReMix method, which demonstrates high generalization ability and outperforms other state-of-the-art person re-identification (Re-ID) methods.

The high generalization ability of ReMix is achieved by leveraging a mixture of heterogeneous (multi-camera and single-camera) data during training. To the best of our knowledge, this is the first work that investigates training on a mixture of multi-camera and single-camera data in person Re-ID.
What is Person Re-ID?
Person Re-ID is a crucial task in computer vision that involves recognizing and matching the same individual across different camera views. It plays a significant role in various applications, including surveillance, security, smart cities, marketing, and analysis of sport events.
Unlike face recognition, which relies on facial features, Re-ID focuses on full-body appearance, including clothing, posture, and carrying objects, making it a more challenging task due to variations in lighting, occlusions, background clutter, and viewpoint changes.
In our paper, we consider a much more complex and practical oriented task of generalized person Re-ID.
Standard Person Re-ID vs Generalized Person Re-ID
While standard person Re-ID models aim to match individuals across different camera views within a single dataset, Generalized Person Re-ID focuses on improving model performance when applied to unseen datasets. This aspect is crucial because real-world deployment requires models to generalize well to new environments without additional fine-tuning.
The Task Remains Unsolved
Modern Re-ID methods still have a weak generalization ability and experience a significant performance drop when capturing environments change, which limits their applicability in real-world scenarios.
Why?
The main reasons for the weak generalization ability of modern methods are the small amount of training data and the low diversity of capturing environments in this data.
In person Re‐ID, the same person may appear across multiple cameras from different angles (multi‐camera data), and such data is difficult to collect and label. Due to these difficulties, each of the existing Re‐ID datasets is captured from a single location.
Is there any other data?
Besides multi-camera data, there also exists single-camera data. The latter is much easier to collect and annotate. For example, such images can be automatically extracted from various YouTube videos. These datasets are diverse in terms of the individuals they contain as well as the variety of capturing environments.
| Dataset | #images | #IDs | #scenes |
|---|---|---|---|
| CUHK03-NP | 14,096 | 1,467 | 2 |
| Market-1501 | 32,668 | 1,501 | 6 |
| DukeMTMC-reID | 36,411 | 1,812 | 8 |
| MSMT17 | 126,441 | 4,101 | 15 |
| LUPerson | >4M | >200K | 46,260 |
Okay, let's use single-camera data and that's it!
Not everything is so simple. Single‐camera data is much simpler than multi‐camera data in terms of the person Re‐ID task: in single‐camera data, the same person can appear on only one camera and from only one angle. Directly adding such simple data to the training process degrades the quality of Re‐ID.
Multi-camera data is much more complex in terms of person Re-ID: background, lighting, capturing angle, etc., may differ significantly for one person in multi-camera data. In contrast, images of the same person are less complex in single-camera data.

Therefore, single‐camera data is currently used only for self‐supervised pre‐training.
What is Self‐supervised Pre‐training?
Self-supervised pre-training is an approach for training neural networks using unlabeled data to learn high-quality primary features. Such pre-training is usually performed by defining relatively simple tasks that allow training data to be generated on the fly, for example: context prediction, solving a puzzle, predicting an image rotation angle.
After self-supervised pre-training, models are typically fine-tuned for the target task. In our case, models are fine-tuned on multi-camera Re-ID datasets.
Proposed Method
In our paper, we propose ReMix, a generalized Re-ID method jointly trained on a mixture of limited labeled multi-camera and large unlabeled single-camera data.
Our Hypothesis
We hypothesize that self-supervised pre-training on single-camera data has a limited effect on improving the generalization ability of Re‐ID methods because subsequent fine‐tuning for the final task is performed on relatively small and non‐diverse multi‐camera data.
To solve the problem mentioned in our hypothesis, ReMix smartly adds diverse (but simple) single-camera data to mini-batches in addition to non-diverse (but hard) multi-camera data. This approach allows our method to achieve better generalization by training on diverse single-camera data.
We also experimentally validate our hypothesis regarding the limitations of self-supervised pre-training and show that our joint training on two types of data overcomes them.
Our main contibutions:
- A novel data sampling strategy that allows for efficiently obtaining pseudo labels for large unlabeled single‐camera data and for composing mini‐batches from a mixture of data.
- A new Instance, Augmentation, and Centroids loss functions adapted for joint use with two types of data, making it possible to train ReMix.
- Using self‐supervised pre‐training in combination with the proposed joint training procedure to improve pseudo labeling and the generalization ability of the algorithm.
The Preamble
Before describing our ReMix method in detail, let's formally define the training datasets:
- Labeled multi-camera data consist of image-label-camera triples \( \mathcal{D}_m = \left\{ (x_i, y_i, c_i) \right\} _{i=1}^{N_m} \) , where \( x_i \) is the image, \( y_i \) is the image's identity label, and \( c_i \) is the camera ID.
- Unlabeled single-camera data \( \mathcal{D}_s \) is a set of videos \( \left\{ \mathcal{V}_i \right\}_{i=1}^{N_s} \) , where each video \( \mathcal{V}_i \) is a set of unlabeled images \( \left\{ \hat{x}^i_j \right\}_{j=1}^{N_s^i} \) of people.
In single-camera data, each person appears on only one video.
Overview
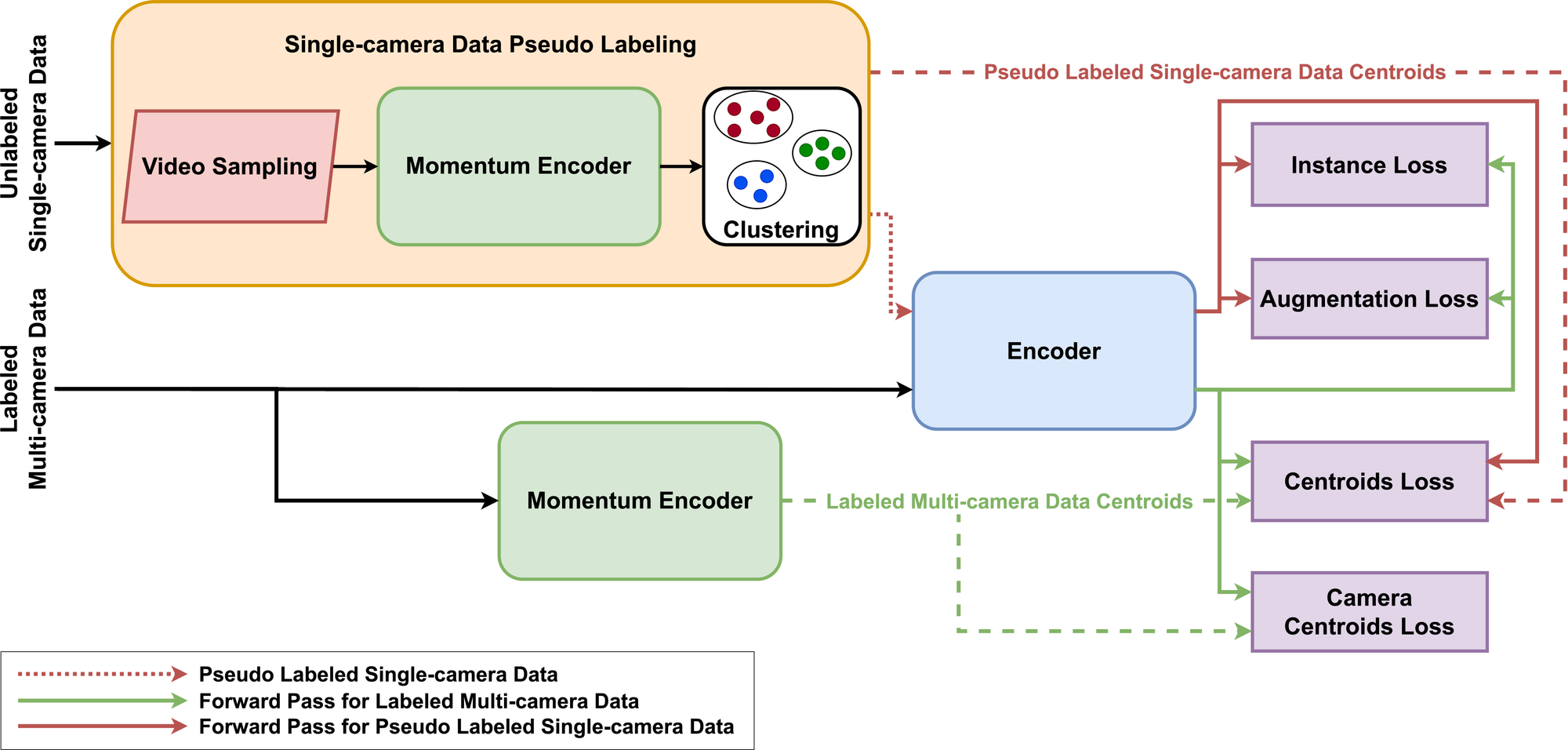
Let's outline the ReMix training process based on the scheme above (it's simple, really):
- At the beginning of each epoch, all images from the multi-camera data pass through the momentum encoder to obtain centroids for each identity (bottom part of the scheme).
- Simultaneously, videos are randomly sampled from the unlabeled single-camera dataset, and images from the selected videos are clustered using embeddings from the momentum encoder and pseudo labeled (top part of the scheme).
- Mini-batches containing a mixture of labeled multi-camera and pseudo labeled single-camera data are composed.
- Mini-batches from the previous step are fed to the encoder as input.
- To train the encoder, the following new loss functions are used:
- The Instance Loss, the Augmentation Loss, and the Centroids Loss are calculated for both types of data
- The Camera Centroids Loss is calculated only for multi-camera data.
- The encoder is updated by backpropagation, while the momentum encoder is updated using exponential moving averaging.
Why Are You Using Two Encoders?
The use of the encoder and the momentum encoder allows for more robust and noise-resistant training, which is important when using unlabeled single-camera data.
How to Use ReMix During Inference?
During inference, only the momentum encoder is used to obtain embeddings. Therefore, ReMix can seamlessly replace other methods used in real-world applications.
Data Sampling
Pseudo Labeling
Since ReMix uses unlabeled single-camera data, pseudo labels are obtained at the beginning of each epoch using the following algorithm:
- A video \( \mathcal{V}_i \) is randomly sampled from the set \( \mathcal{D}_s \).
- Images from the selected video are clustered by DBSCAN using embeddings from the momentum encoder and pseudo labeled.
- This procedure continues until pseudo labels are assigned to all images necessary for training in one epoch.
This approach reduces computational costs in pseudo label generation and ensures training stability with unlabeled data.
In this way, our method iteratively obtains pseudo labels for almost all images from the large single-camera dataset.
Mini-batch Composition
In ReMix, a mini-batch is composed from a mixture of images from multi-camera and single-camera datasets as follows:
- For multi-camera data, \( N^m_P \) labels are randomly sampled, and for each label, \( N^m_K \) corresponding images obtained from different cameras are selected.
- For single-camera data, \( N^s_P \) pseudo labels are randomly sampled, and for each pseudo label, \( N^s_K \) corresponding images are selected.
Thus, the mini-batch has a size of \( N^m_P \times N^m_K + N^s_P \times N^s_K \) images.
Loss Functions
As was mentioned before, in ReMix we propose three new loss functions to make training of our method possible. These loss functions are adapted for joint use with two types of data. In order not to overload this review, I will describe the basic idea of each proposed loss function:
- The Instance Loss brings the anchor closer to all positive instances and push it away from all negative instances in a mini‐batch. Thus, the Instance Loss forces the neural network to learn a more general solution.
- The Augmentation Loss brings the augmented version of the image closer to its original and pushes it away from instances belonging to other identities in a mini‐batch. This addresses the issue of changes in the distribution of inter‐instance similarities caused by augmentations.
- The Centroids Loss brings instances closer to their corresponding centroids and pushes them away from other centroids.
You can find a more detailed description of them in the original paper.
You Mentioned the Camera Centroids Loss. What is it?
In addition to the proposed loss functions, in ReMix, we calculate the Camera Centroids Loss only for multi‐camera data. The main idea of this loss function is to bring instances closer to the centroids of instances with the same label, but captured by different cameras. Thus, the intra‐class variance caused by stylistic differences between cameras is reduced.
Temperature Parameters
Since multi‐camera and single‐camera data have different complexities in terms of person Re‐ID, we balance them by using temperature parameters in the Instance and Centroids loss functions.
In our paper, we experimentally validate our hypothesis about the different complexities of multi-camera and single-camera data: the best Re-ID results are achieved when we use higher temperatures for single-camera training in the Instance and Centroids loss functions.
Why does it work? Higher temperature values make the probabilities closer together and complicates training on simpler single-camera data.
Proof-of-Concept
In our paper, we conduct a series of experiments to demonstrate the effectiveness of the proposed idea of joint training on multi-camera and single-camera data. Indeed, using single-camera data in addition to multi-camera data significantly improves the generalization ability of the algorithm and the quality of generalized person Re-ID.
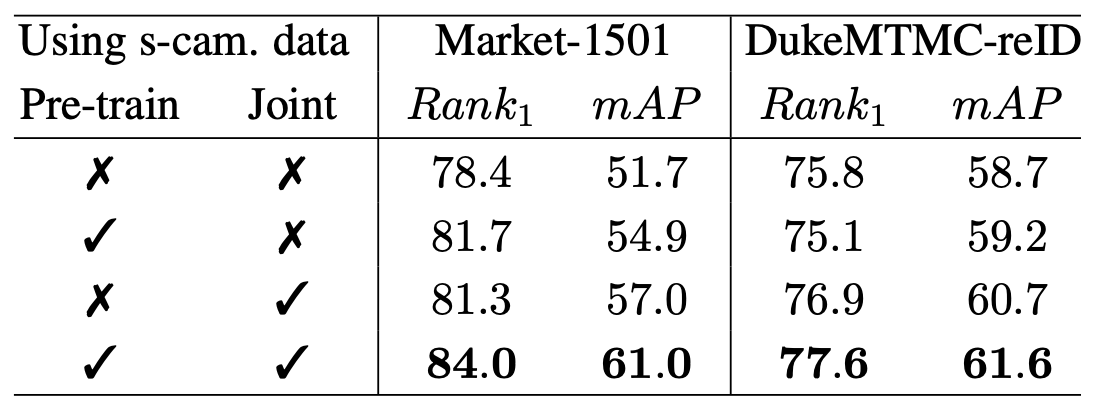
Moreover, the effectiveness of our approach is demonstrated in comparison with self-supervised pre-training: the model trained using the proposed joint training procedure achieves better accuracy than the self-supervised pre-trained model. Thus, we experimentally confirm the importance of data volume at the fine-tuning stage and validate our main hypothesis.
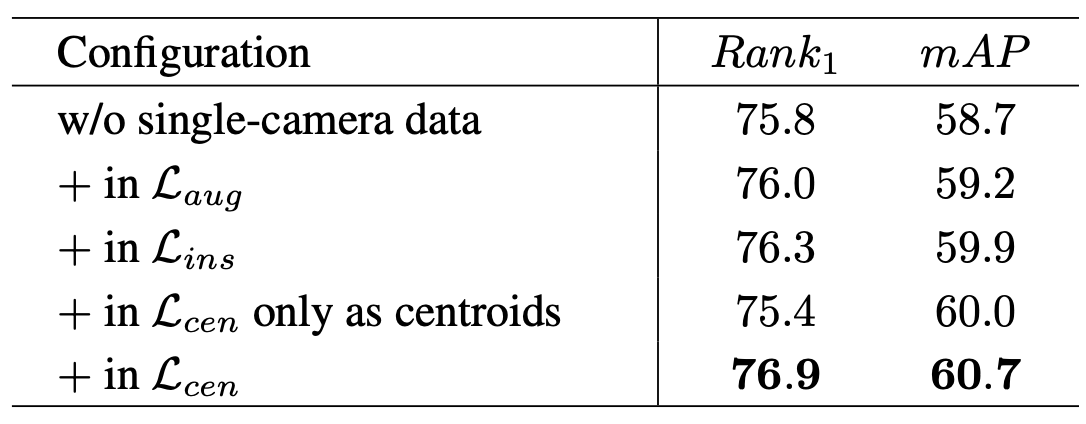
Additionally, we show that our loss functions are successfully adapted for joint use with two types of data. In our study, we gradually add single-camera data in losses and measure the final accuracy. Finally, each loss function added to a combination improves the performance, and using all losses with single-camera data jointly provides the highest quality.
Comparison with State-of-the-Art Methods
We compare our ReMix method with other state-of-the-art Re-ID approaches using two test protocols: the cross-dataset and multi-source cross-dataset scenarios. Thus, we evaluate the generalization ability of ReMix in comparison to other existing state-of-the-art Re-ID methods.
What is difference between these protocols?
- In the cross-dataset scenario, we train the algorithm on one multi-camera dataset and test it on another multi-camera dataset.
- In the multi-source cross-dataset scenario, we train the algorithm on several multi-camera datasets and test it on another multi-camera dataset.
Our comparison demonstrates that our ReMix method outperforms others according to both protocols.
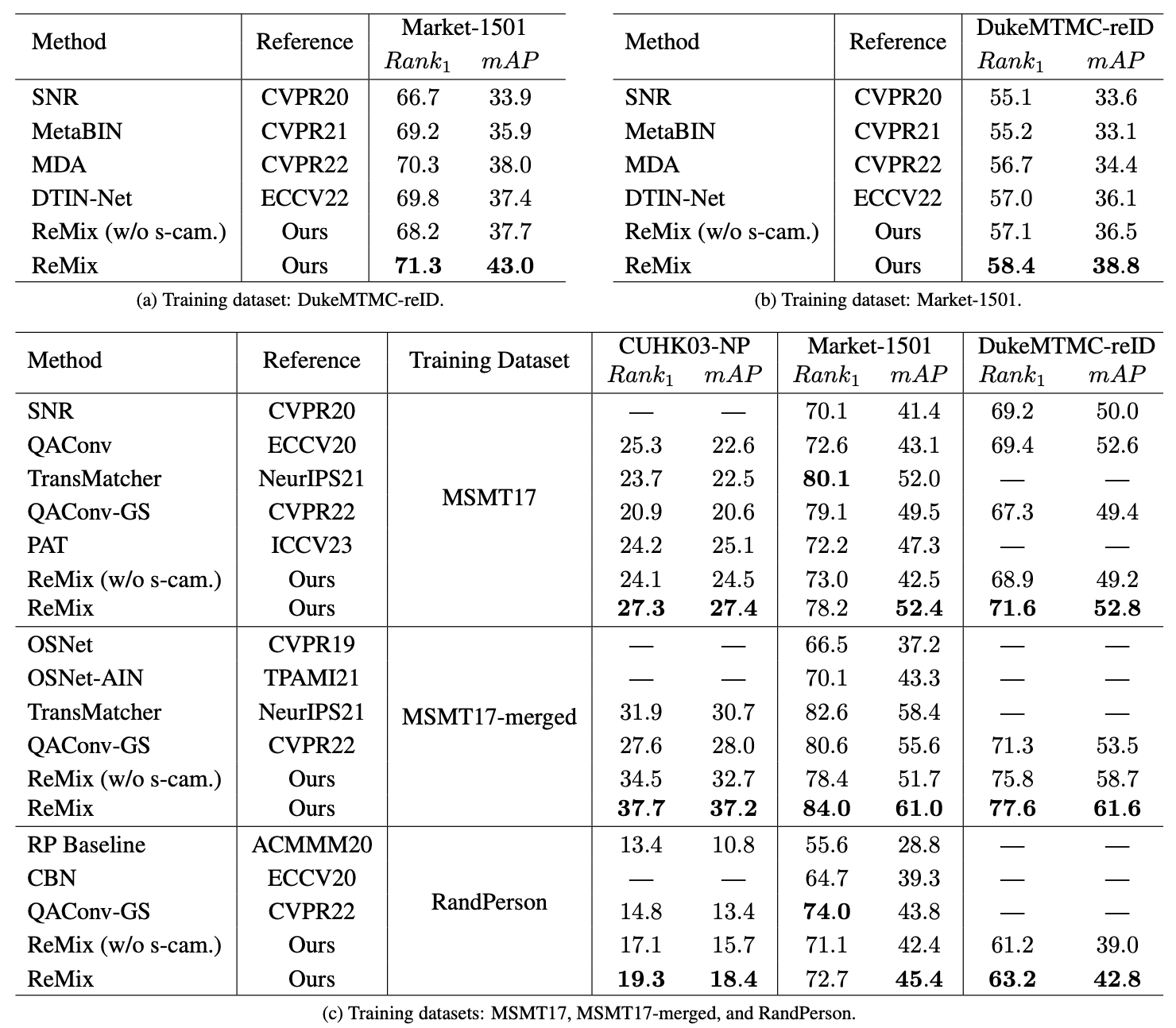
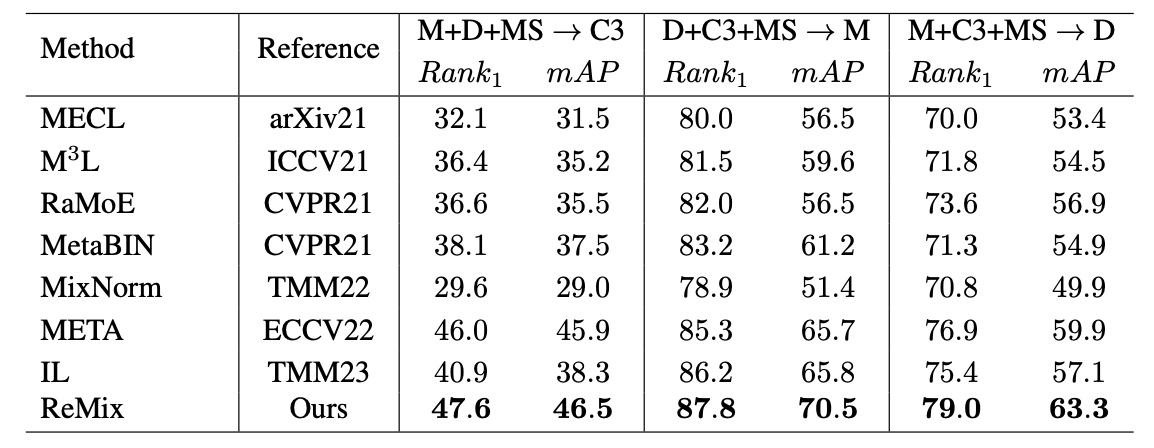
It's worth noting that most existing state-of-the-art approaches improve generalization ability by using complex architectures. In contrast, the high performance of our method is achieved through the training strategy that doesn't affect computational complexity, so our method can seamlessly replace other methods used in real-world applications. This fact proves the consistency and flexibility of ReMix.
Conclusion
In our paper, we introduced ReMix, a novel person Re-ID method that effectively leverages both multi-camera and single-camera data to enhance its generalization ability. Our extensive experiments confirm that simultaneous use of single-camera data with multi-camera data significantly improves the quality of generalized person Re-ID.
We believe our work will serve as a basis for future research dedicated to generalized, accurate, and reliable person Re-ID.